




























The Digital Influence on Sales
In this article we will have a look at how AI and ML can revolutionize the aftermarket auto part sales through its effect on proper product classification. The pandemic influenced shopping behavior of consumers and the explosion in general eCommerce players has affected the automotive aftermarket parts industry too. The digital influence on the purchase decision of customers is increasingly playing a crucial part in sales. Even in cases where a customer buys from a store, the product is well researched online. Studies show that nearly 93% of auto parts sales happen with buyers researching online before purchase. Over half of auto parts buyers go to manufacturer websites during the pre-purchase research phase. In more than four out of five parts, buyers base their decision to buy on a brand’s online presence. So, offline auto part sale is also influenced by content available online.
The growing trend of manufacturers selling directly to consumers is another trend to follow. More manufacturers are short-circuiting traditional distribution channels for auto parts and selling directly to consumers
The proliferation of eCommerce and online catalog was enabled by standards (ACES®/PIES®) developed. This helped in one of the most important aspects of cataloging and eCommerce product/part categorization and their compatibility with a vehicle and model. This is very important not only in attracting the customer but in their retention based on experience, easy access and search functionalities. Artificial Intelligence (AI) and Machine Learning (ML) is likely to fuel the next wave of growth for the eCommerce players in the auto aftermarket segment.
AI & ML in AutoParts Aftermarket – Product Classification
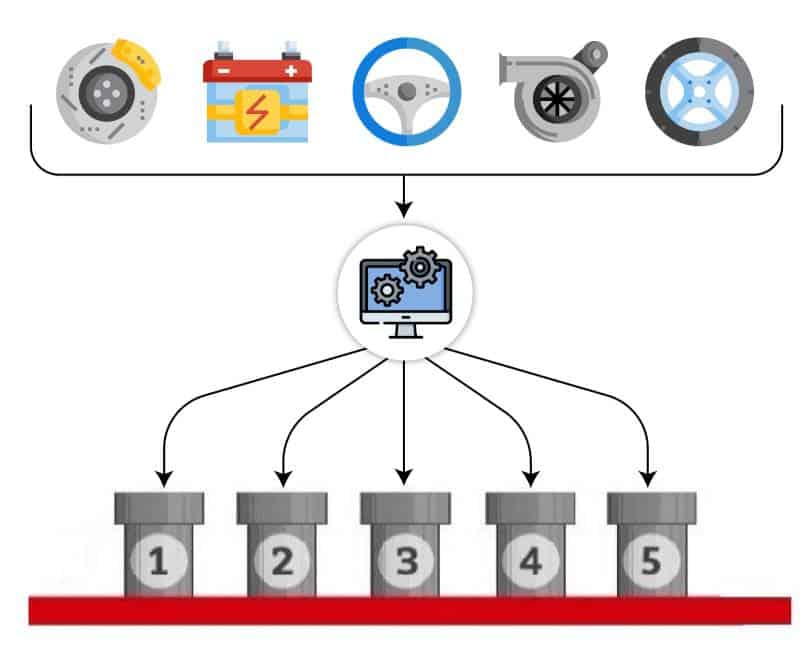
Artificial Intelligence and Machine Learning tools are backbone of eCommerce marketplaces for data insights for business and can be used for – product hierarchy/taxonomy identification using product classification techniques and attribute normalization. Auto Parts from various suppliers must be correctly categorized as per the seller’s product hierarchy/taxonomy before they can be listed in the webstores. Attributes need to be standardized for different product categories for facilitating quality search in the webstore. This has traditionally been a time-consuming manual effort. ML techniques show the promise of speeding up these processes significantly.
Various machine learning techniques allow a flexible architecture to use a wide range of data types including images, product descriptions, part numbers. Also, since category to attribute mapping is available, these relationships may also be used to classify the product, leading to increased accuracy. Image matching techniques can also be incorporated to further improve accuracy. The use of deep learning NLP algorithms also helps in product title matching classification for cases where same product has different product title texts
The classification of levels can also be a level up or level down. The level up involves a machine learning model which predicts product type for each item and maps the higher levels based on the current taxonomy hierarchy mapping. The level down can contain two machine learning models, one for predicting macro category and the other for micro categories within that macro category.
Training the ML model
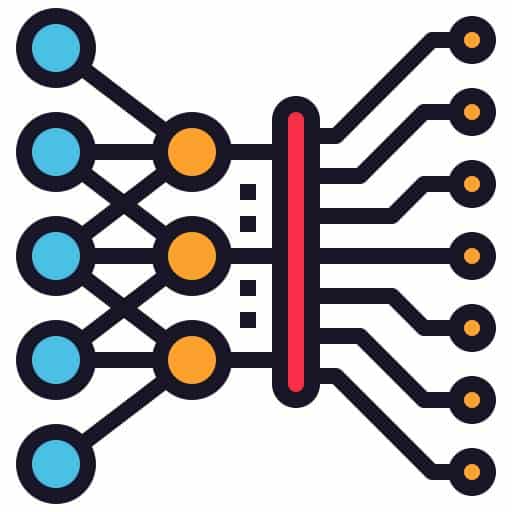
The first and important step in implementing a machine learning model is preparing a digital data set to learn and validate the correctness of the algorithm. This would involve data extraction, data aggregation, data cleaning / transformation. Input data set from suppliers consist of product information like title, description, attributes and the category to which product is mapped (Part Terminology) manually. Data set is split into 80:20 /90:10/70:30 ratio randomly for training the model and for validating the trained model. The cases in which prior taxonomy/ product hierarchies are not available for training or it’s a new product which is not part of training set makes use of zero shot learning for predictions. These techniques are still in an experimental stage.
A very important aspect of this training is having the right data set to train the model. This is very often a challenge. Non-standard and inadequate descriptions and attributes would need to be cleaned up and an element of manual effort is inevitable for good quality matches to be churned out automatically. This is posing a barrier to the fast adoption of these techniques.
Category Prediction
The machine learning trained model acting on any input data set can provide as output the prediction along with the confidence the algorithm has in its prediction. The threshold level selected decides the percentage of products automatically labelled which then decides the accuracy of prediction. They are inversely related. The threshold probability beyond which we approve the category labeling automatically is selected based on the trade off with business needs. Selecting the model and classifier is an art of trial and error where the time taken by model and its accuracy are all factors considered. The percentage of products thus labelled automatically crossing the threshold is defined as coverage and the percentage of such automatically labelled products correctly labelled is accuracy. The very high ratio of automatically classified products leads to a reduction in costs and time.
These models can work on Naives-Bayes classifier, K-nearest-neighborhood or tree classifier. Increasingly deep learning algorithms based on neural networks like MLP, Distilbert, DNN, CNN, LSTM, CNN-LSTM and NLP tools like GPT-3, spaCY, NLTK, Gensim are being used to address similar areas. Organizations can also leverage NLP to enhance searching capabilities in a data catalog like to extract meta information from various unstructured datasets such as images, videos, pdf. As seen earlier the model to use is a business decision between the business, operations and data teams.
These models may be implemented with the help of library tools like Scikitlearn, Tensorflow, Pytorch, Weka, Jupyter Notebooks/Labs for data cleaning and transformation, pandas for data sharing across teams and developers including external, Apachespark MLib.
Conclusion
Use of machine learning can give a significant help to improve quality of web site listing, search experience, recommendations and reduce the part returns for web stores, cost controls, scalability and increase in revenue. Manual data cleaning interventions would need to be done to ensure that the quality of the matching process is optimal.